What after Kaleidoscope: Error location
2025-02-27
Prologue
Hi everyone, wow, it's been a quick minute since I posted a new article. How's everyone doing :) I'm still trucking away at life applying to compiler jobs as well as schooling at Berk. Hope everybody's doing great :)
This article is for people who might be asking:
"Ok, I've read the Kaleidoscope series and done its llvm tutorial already. What's next?"
More specifically, the article is about adding primitive support for error reporting to the toy compiler. The article assumes some familiarity with lexer, parsing and the visitor pattern. Some familiarity with the parser and its abstract syntax tree (AST) construction from the llvm tutorial is helpful but not necessary.
Besides that, the article is also to share my software design decisions regarding my compiler's diagnostics and to improve my technical writing ability.
As is tradition :) I also wanna share some songs with you. The two songs are Valentine and Into my arms, both by COIN, one of my fav bands :) To me, Valentine is this flirty and fun—like a rush of butterflies, you know? It’s got that energetic, dreamy beat that feels like falling in love for the first time. But Into My Arms' this pure intimacy, deep, and emotional calling. It's as if the singer knows what they really wants and they're just pulling at the heartstrings and begging you to just melt into someone’s embrace.
Sigh, at this point you might be thinking I must be writing blogs just to share and review music, huh? :) Smh
I hope you enjoy :) (both the songs and the blog hahah)
Introduction
Compiler diagnostics is an important aspect in one's compiler. From erroring out on the programmer's mistake to providing warnings or giving diagnostics, the ability to accurately locate the location of the pesky problems to said programmer is proven to be extremely valuable: only providing to the programmer the row and column number of where an error occurs is less helpful and more confusing than a compiler pointing, tracing and explaining an error to a programmer.
The article then discusses a way to improve upon the llvm Kaleidoscope toy compiler in the diagnostic aspect for the user. The picture below shows the difference between a primitive and a somewhat sophisticated error diagnostics scheme and is implemented as part of the sammine compiler.
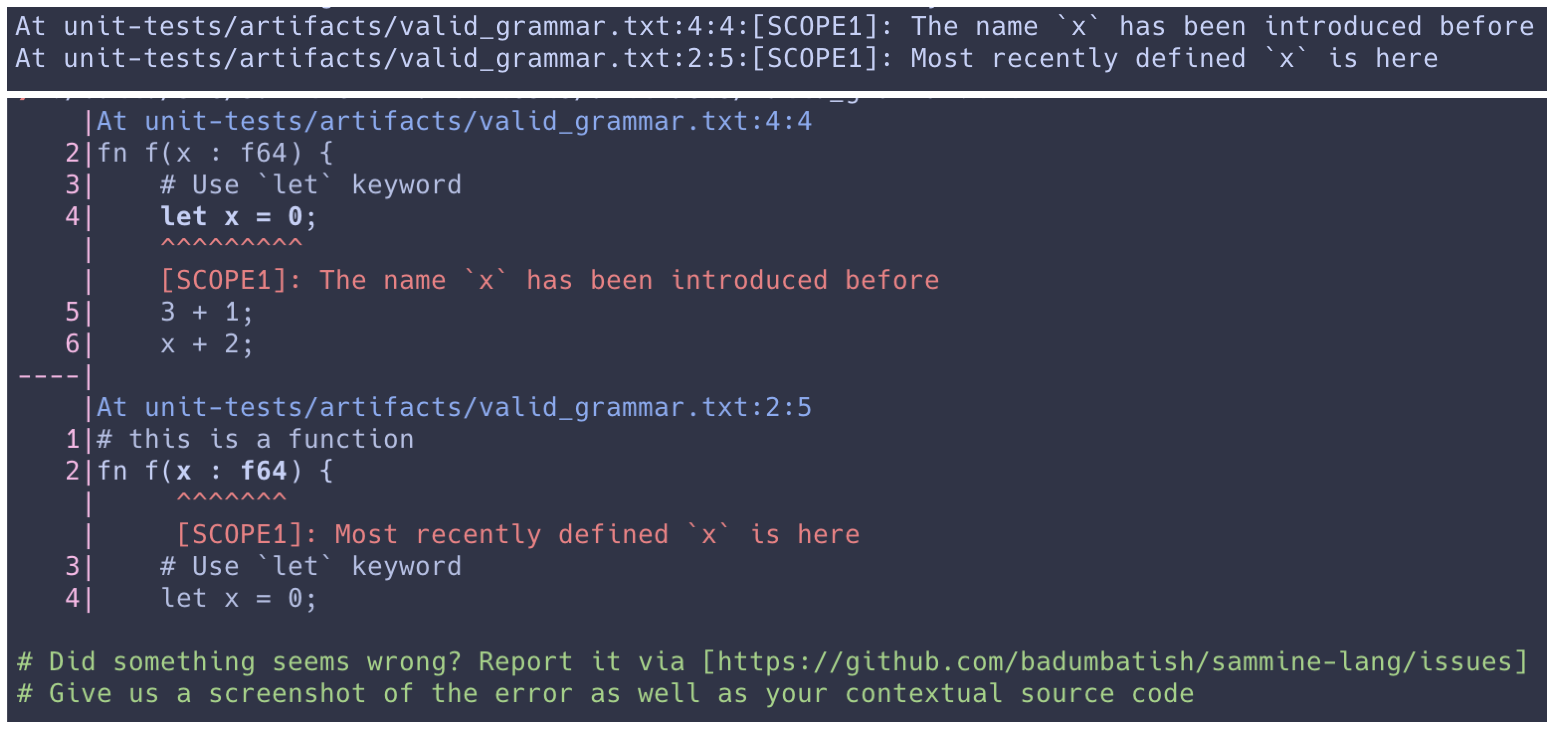
Location, Reporter, Locator and Reportee
Let's start with a simple description of the problem and a simple answer to the said problem.
Given a string (which is the input of the compiler), and a starting point index and an ending point index of said string, indicate the component (either a token or a subpart of some AST) that is faulty.
Below shows a string of a variable definition and its corresponding starting and ending point in
the input
string:
start of decl
| end of decl
| |
↓ ↓
01234556789
let x = 1;\eofHere, the starting point for the let expr has index 0 in the string, and the ending point for the let expr has index 7 in the string (the semicolon at 8 is not counted).
From first principles, how can a compiler consolidate the location of these tokens: let, x, =, 1
together and understand that the declaration spans from 0 to 7?
Let us define the class Location, Reportee
and Reporter currently implemented as part of the compiler and see how all of these building blocks fit in together.
The Location class
The Location class is basically two indices, indicating the location of a construct in the
input string. The first index
source_start
signifies the
starting location of a component and vice versa for source_end. If a construct in the compiler (a token or an AST)
only occupies a single space, then source_start == source_end.
When two Locations come together to form one singular Location, we take the minimum of all
source_start and the maximum of all the source_end. This is implemented as the pipe operator | for the class:
// Combine two locations
Location operator|(const Location &other) const {
Location result;
result.source_start = std::min(source_start, other.source_start);
result.source_end = std::max(source_end, other.source_end);
return result;
}
void operator|=(const Location &other) {
source_start = std::min(source_start, other.source_start);
source_end = std::max(source_end, other.source_end);
}Let's look at an example, given the string of a binary expression x+y, since x takes the Location(0,0), y
takes the Location(2,2). The location for the resulting binary expression is Location(min(0,2), max(0,2)) = Location(0, 2).
Another thing to notice is that the Location class offers modifiers on source_end, this is mostly useful in the
case of lexing different token such as + and += - often in sammine I have to backtrack and thus this is really
helpful.
The Reportee class
Given a location, we need a message to be associated with it, together with the diagnostic kind: Is this message an error? Is it a warning? Is this just to provide the programmer/compiler writer with some extra information for an informed decision?
The class that takes care of this is the Reportee class. It defines different ReportKind such as error,
warn or diag for error, warning or diagnostics respectively. It also provides abstraction such as add_error(),
add_warn() or add_diag for said ReportKinds. The input to these add_*() call is a Report type, which is
just a tuple of ReportKind, Location, std::string.
Who's calling add_error() and add_warn()? Whichever phase the compiler needs to communicate with the
programmer
about, that phase will inherit from this Reportee class and use these utilities functions. The sections on Lexer and
Parser will go over these finer details.
Besides this, the Reportee class also carries size_t of error_count, warn_count and
diag_count to be used as statistics for the Reporter class, which is the topic of our next subsection.
The Reporter class
The compiler
needs to 'report' messages coming from different stages (Reportee) such as lexing, parsing or type checking, of
which the Reporter class is in charge.
Upon construction, it takes in a file name, the source code string, and the context radius. For example, if the context radius is 2, then if we're reporting on 1 line of code at line 3, we would print out from line 1 to line 5 (via the Locator class).
Then it splits this source code string into different strings seperated by newlines, and constructs a std::vector
of pairs of the running sum lengths of all the strings up to the current string and the current
string. This is implemented as Reporter::get_diagnostic_data and the result is stored as an intermediary
ingredient for the Locator class:
using DiagnosticData = std::vector<std::pair<std::size_t, std::string_view>>;
DiagnosticData Reporter::get_diagnostic_data(std::string_view str) {
DiagnosticData result;
size_t start = 0;
while (start < str.size()) {
size_t end = str.find('\n', start);
if (end == std::string_view::npos) {
// Add the last substring if no more newlines are found
result.push_back({start, str.substr(start)});
break;
}
// Add the substring excluding the newline character
result.push_back({start, str.substr(start, end - start)});
start = end + 1;
}
return result;
}Then, the Reporter class takes in a Report, a tuple of ReportKind, Location, std::string and
print the message via stderr to the programmer; it also knows that for a specific
ReportKind, which color should be printed.
The Locator class
You must be wondering, just the linear (source_start, source_end) indices is not enough, this result is just
the
bare
minimum.
Somehow the compiler needs to be able to map a location of (source_start, source_end) to the starting and ending rows and columns for easier visualization.
What if we also want some lines of code before and
after the concerning line of code for more context, how would we do that?
Maybe if the Location needed to be
reported is one,
or two,
or
three lines only, and it'd be very helpful to hone in and point out the mistake for the programmer.
To do this, the Locator, with the source_start and source_end, consecutively performs binary search on the
DiagnosticData
given by the Reporter,
and
returns the row and column needed for reporting.
This is why we're making DiagnosticData to be a vector of
pairs where the first element is monotonically increasing: we can binary search on the first element of the pair to
get out the index of the vector (which tells us what row it is), as well as the second element of said index (which
allows us to print out the involving row). The reduction from to is a much-needed break once the
compiler input exceeds 10,000 rows or more with multiple files.
It then subtracts and adds, respectively on these rows obtained from
source_start and source_end, the provided context_radius to get the final rows and columns
result,
usable by the Reporter class.
Tokens (and the lexer)
Wewwww.... Let's talk about the tokens and the lexer. When given the source code as a string (maybe via a file), the lexer scans from left to right on that string, each time incrementing the index on the string and returning a token. Thus, this is the basis of our class Location.
In sammine, tokens are (loosely) modeled as:
class Token {
public:
TokenType type;
std::string lexeme;
Location location;
Token(TokenType type, std::string lexeme, Location location)
: type(type), lexeme(std::move(lexeme)), location(location) {}
};and for the lexer:
class Lexer : public sammine_util::Reportee {
private:
sammine_util::Location location;
std::vector<Token> tokStream;
...One thing to note is after we've recognized a token together with its Location, we update the Location of the
Lexer via update_location().
void Lexer::updateLocation() {
location = sammine_util::Location(location.source_end, location.source_end);
}The reasoning for this is that if we don't do this, then in the following example, the
token += as well as the token b will have inaccurate locations, spanning from the start of the input to the
current index.
Location a: (0, 0)
| Location +=: (0, 3)
| | Location b: (0, 5)
↓ ↓ ↓
012345
a += bAST nodes (and the parser)
After we've produced our tokens, the parser takes in the stream of tokens and produces our ASTs. An AST is created after identification for a specific ordering of some tokens.
For this newly created AST, the simple thing to do is to combine all the AST's token's location into one. Below shows pseudocode for that
AST_construct(Token tok1, Token tok2, ...) {
...
AST.Location = first token location of AST
For all tokens T that made up the AST:
AST.Location |= T.location
...
}In AST construction, we follow quite literally what the parser is parsing, for the following example: there is an AST of function with an AST of expr being nested in it (as a list of expressions).
fn f(x : f64) {
let y = 0;
}The code block then translates to this pseudocode c++ structure:
class AST_Func { // this stands for fn f
AST_Prototype prototype {
std::string func_name // stands for the name `f`
std::vector<AST_TypedVar> function_arguments // this stands for `x : 64`
}
AST_Block function_block {
std::vector<AST::Expr> statements // this stands for a singular `let y = 0;`
}
}Study case: scope checking visitor
Knowing how a Location plays out in a lexer's token and parser's AST is helpful, but so what? Operations on the
AST such as scope checking or type checking also needs reporting on where a programmer went wrong, the responsibility
is
not just within the lexer
and the parser.
In this case, let's see how we
can use
Location to inform our programmers of some scope problem.
In sammine, given a function, the compiler should error out if an unknown variable is referenced or if
a variable is defined twice (the language prevents shadowing variable).
Given the following code:
fn f(x : f64) {
let x = 0;
...
}the compiler should error out since we don't allow shadowing of a variable:
To do this, we set up an AST visitor first, where each kind of visitor visits an outlying AST out first, perform
something (walk) on that AST (preorder), then
visit its children AST, and then comes back and perform another action (walk) on the
AST out (postorder).
For paraphrasing purposes, on how to set up the AST visitor pattern, we separate the step between visiting an AST and performing the pre- and post-ordering operation on said AST.
The action of perform the pre- and post-ordering operation on an AST is called walking and is implemented as
pre_order_walk and post_order_walk.
Without specified otherwise, readers (and programmers) can assume that this is the execution ordering for a visitor:
Visit(AST):
pre_order_walk(ast)
~ recursively visit each element (sub AST) in the AST ~
post_order_walk(ast)Following the assumption that a visit to AST will ultimately and recursively visit each element of the AST as well,
the following sections on scope checking
will only discuss the pre_order_walk() and the post_order_walk()
class Lexical Scope
The Lexical Scope class stores information about variable declarations and can be used to query whether a certain variable (represented by a string) existed in a scope or not.
For example, in a function f, if we haven't defined a variable x but we're using it, it is considered
illegal in
sammine .
To do this, the scope class consists of a mapping symbol_to_loc between symbols to locations as well as a
reference to
the parent
scope (just in case we want to implement some kind of lambda).
The reason to have a mapping between symbols and locations is when we have a clash of symbol, we can error out and report on the location that is registered for the clashed symbol.
Visiting
The scope visitor will, of course, visit different ASTs at play. However, what we're concerned with is how these orders affect what we want to do, in this case, scope checking. What we want to do next is to declare a few rules for the scope visitor to register a scope and check for variable shadowing in a scope. Since we have seperated the pattern into the visit step and the walk step.
pre_order_walk(FunctionAST): We push a newly created scope on the scope stack.post_order_walk(FunctionAST): We pop that stack out of the scope stack
Let's talk about VarDefAST's walk first, after which the walk of PrototypeAST will make more sense. A VarDefAST basically just contains a variable definition:
pre_order_walk(VarDefAST): We check if a variable namedvarthat we want to define has already been defined or not. If it has, then we query the location that previously definedvarviasymbol_to_loc[var]andadd_error()both the previous location and the currentVarDefAST's location.post_order_walk(VarDefAST): Do nothing.
Since PrototypeAST, the definition of a FunctionAST, contains a vector of variable declaration, we apply the same
procedure that we have for VarDefAST on PrototypeAST.
pre_order_walk(PrototypeAST): Same aspre_order_walk(VarDefAST)for its vector of variable declaration.post_order_walk(PrototypeAST): Do nothing.
Result
Yayyy! Now, if we call the scope checking visitor and let it recursively visit down to each function and consequently to each variable definition, we'll get something like this to the terminal for the following program.
# this is a function
fn f(x : f64) {
# Use `let{:cpp}` keyword
let x = 0;
3 + 1;
x + 2;
x - 2;
x = 2;
}
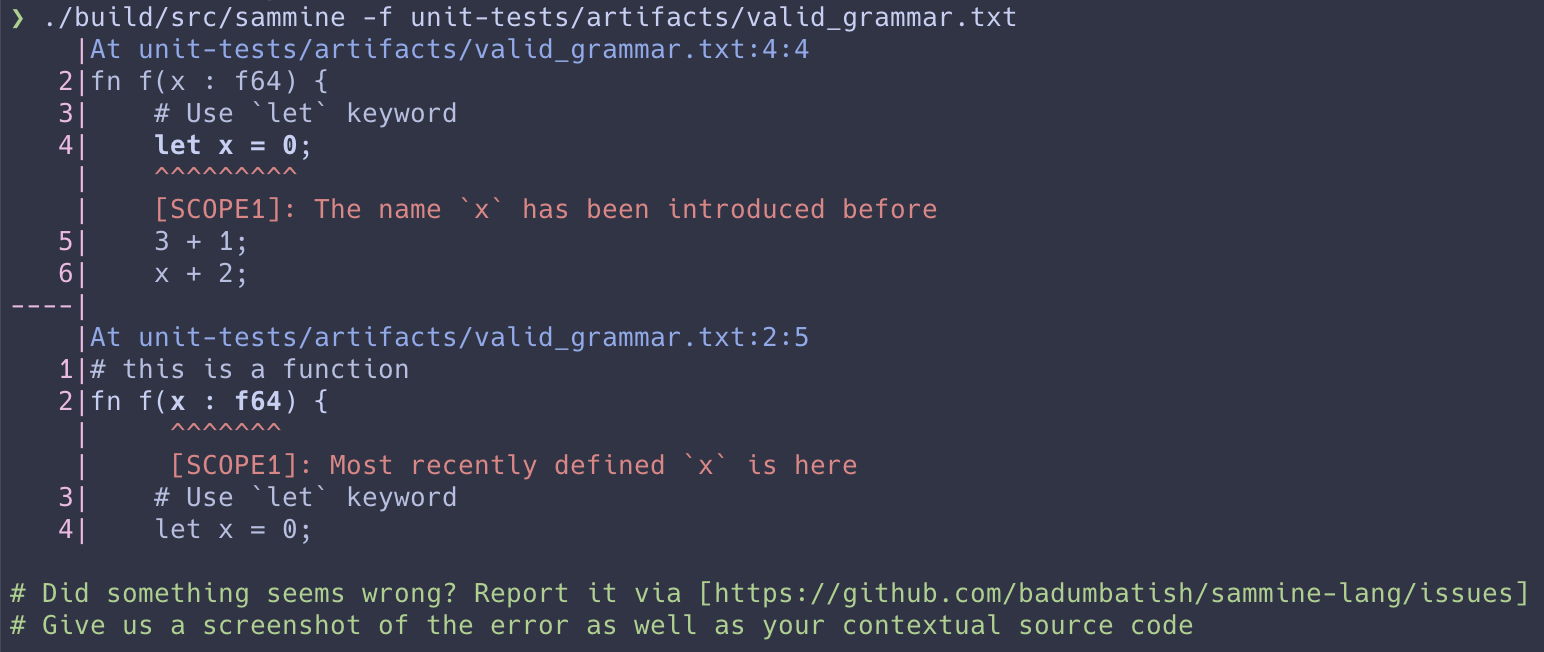
What's next?
That's it from me for now!
Implementing diagnostics for my compiler was really fun. I knew that being able to abstract and reuse code is a crucial aspect of software engineering, and showcasing this in an actual project is a big deal for me. Different stages in a compiler needing diagnostics mean that unless I reuse code, repetitive concepts will keep popping up.
There are still features to be desired and to be implemented. One of them is chaining diagnostic locations: figuring
out a clean way to chain together multiple diagnostic would be really helpful for programmers. Another one is
propagating the location info down to LLVM's codegen stage:
this means that we need to somehow conform the Location class to LLVM's debugging location info class.
Interested readers can read about the write up here
After this quick demonstration, hopefully I have motivated you to now implement features like detecting the use of not-yet-defined variables and use of not-yet-defined functions.
I hope you enjoyed the blog! (And the music recommendations as well—heheh.)